


ChatGPT Explained in 5 Levels of Difficulty
The definitive ChatGPT explainer.


Talking robots often come to mind when we think of the future. In December 2022, such a future started seeming closer than ever with the launch of ChatGPT.
As ChatGPT rose to popularity and acquired millions of users in record time, some heralded it as an invention as transformative as the first computers. Naturally, many questions arose around it as it entered the mainstream.
While we can’t answer questions about the future impact of ChatGPT for now with certainty, what we can answer is how ChatGPT works. And that is what we’re going to do in this edition of The Conquest Communiqué.
We explain ChatGPT to you 5 times: first as if you were a Child, then a Teenager, then a College Student, then a Graduate student, and finally an Expert. Even if you knew nothing about this tech before, by the end of this article you’ll have the complete picture and understand ChatGPT at the expert level.
Level 1: Child
Imagine if Doraemon existed in real life. We know for sure that Doraemon, being a robot, does not have a biological brain like we do. Then how could we teach Doraemon to think or talk?
We could make Doraemon read and analyze lots of books and other content written by humans that do have the capability to think and talk.
As he keeps reading, he will begin to notice patterns between letters. “After q, I see u all the time. Often after t, I see an h.” And so on. He will also start seeing bigger patterns; patterns between words. “After the word the, I can see cat, or dog, or…”
Once his training is complete and we tell him something, he can figure out what word can reasonably come after each word based on his training and answer us. Such a Doraemon does exist today, and we call him ChatGPT.

To be honest, the Doraemon analogy is the maximum amount of information you need to cram in your brain if you want to pretend that you understand how LLMs work without actually knowing anything. But if you have been paying attention so far you must be wondering: how can a collection of words chosen simply based on how frequently they appear in language sequences carry any meaning at all, let alone answer specific queries appropriately and creatively?
Level 2: Teenager

If you are a fast texter like me, you probably autocomplete your way through most sentences and dont reread your messages before hitting send. This works just fine until you duck up.
Probably all of us, at some point, have pressed one of the autocomplete options on our phone keyboard again and again just to see what happens. And we noticed the sentences created in this manner didn’t make much sense.
When you read the previous section, the similarities between ChatGPT and autocomplete would have been obvious. Then how can ChatGPT create output that makes sense, while our phone’s autocomplete can not?
This is partly achieved during training through RLHF (Reinforcement Learning from Human Feedback). RLHF is an added layer of human guidance on top of the language model dataset that is used to align the model to what humans want. In RLHF, the response generated by ChatGPT’s language model is presented to a human evaluator. The human evaluator provides feedback on the quality of the response, such as whether it is relevant, accurate, and appropriate for the context. This feedback is then used to update the language model and improve its performance.
Also, ChatGPT doesn’t output words or parts of words – called tokens – simply based on probabilities. It uses techniques like sampling to assign weights (degrees of importance) to each possible token. There are many sampling methods. One is softmax sampling, which scales the probabilities of each possible token so that they add up to 1, and then randomly selects a token based on those scaled probabilities. Such techniques ensure that the tokens make cohesive sense in the output.
And perhaps the most interesting aspect of all this is that not only does the response make sense, it is also creative. This creativity is unlocked through “temperature scaling”. The probabilities of each token are scaled by a factor called temperature, which can be adjusted to make the token selection more or less random. This randomness of choosing the tokens is why we don’t get the same word-for-word response to the same prompt if we input it multiple times, and why the response doesn’t completely match existing texts.
This explanation of ChatGPT’s functioning sheds light on why it can be wrong sometimes. It lacks “common sense” and its logical abilities are nowhere near a rational human’s, who has a capacity to actually understand concepts.
Level 3: College student

ChatGPT, and other chatbots like Google’s Bard and Anthropic’s Claude, are all based on Large Language Models (LLMs), like GPT-3. LLMs are, at their core, a type of neural network.
Neural networks can be thought of as simple artificial idealizations of how human brains seem to work. In our brains, there are about 100 billion neurons, each with the ability to produce an electrical pulse thousands of times per second. These neurons are connected in a complicated network, with each neuron having branches allowing it to pass electrical signals to thousands of other neurons. And in a rough approximation, whether any given neuron produces an electrical pulse at a given moment depends on what pulses it receives from those other neurons—with different connections contributing with different “weights”.
These weights that are assigned to the different parts of the input data are known as parameters in the context of language models, including LLMs. Parameters are the set of learnable values that are adjusted during the training process of the model. By adjusting the parameters during training, the model learns to capture complex patterns and relationships in the input data, allowing it to make accurate predictions on new, unseen data. These parameters can be thought of as connections between words. The more parameters in a model, the more accurately it can make connections, and the closer it comes to mimicking human language.
The LLM’s neural network is capable of Natural Language Processing (NLP), which includes Natural Language Understanding (NLU) and Natural Language Generation (NLG).
NLU involves processing and interpreting user input to extract relevant information. It includes tasks like entity recognition, sentiment analysis, and intent classification. Then, to generate responses to the user query, ChatGPT uses NLG. It is the process of generating natural language text from non-linguistic data. It enables ChatGPT to create responses that are contextually relevant, grammatically correct, and semantically meaningful, by transforming structured data into natural language text.
Interestingly, the GPT-3.5 LLM that the free build of ChatGPT is built on has 175 billion parameters! This large number of parameters is what enables such models to achieve state-of-the-art performance on a wide range of NLP tasks. But to train a model with 175 billion parameters even at the theoretical maximum performance of the Tesla V100 (the world's first GPU to break the 100 TFLOPS barrier of deep learning performance), it would take 355 years!
Then how does OpenAI train the language models powering ChatGPT in a much shorter time?
Level 4: Graduate student
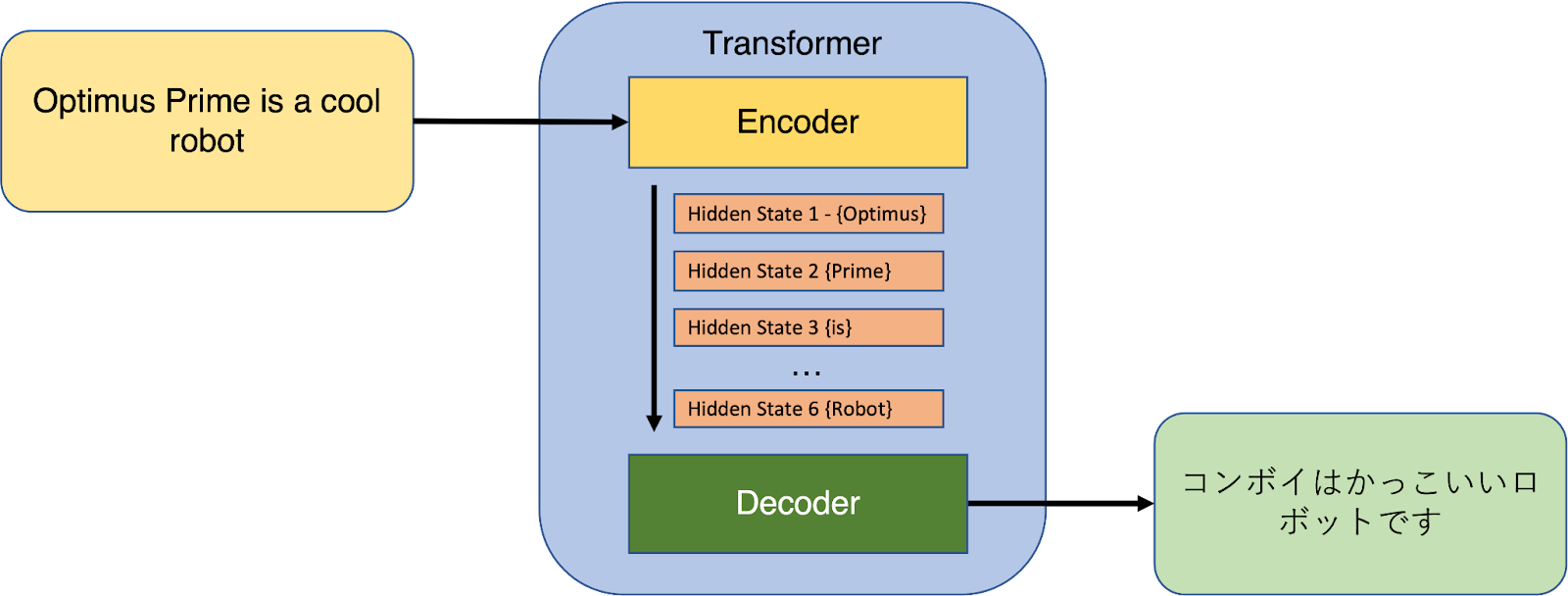
We haven’t fully talked about ChatGPT’s name yet. GPT stands for Generative Pre-Trained Transformer. What makes it “Generative” and “Pre-Trained” we have already discussed; now, on to Transformers. (No, not the Optimus Prime-kind.)
Earlier, machine learning models were primarily based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best-performing models connected the encoder and decoder through an attention mechanism.
Attention in neural networks is a mechanism that allows the network to focus on certain parts of the input data while ignoring others. It is a way to selectively process information by assigning different weights to different parts of the input, based on its relevance to the overall meaning of the sequence. This allows the model to focus on the most important words and ignore the irrelevant ones when generating the summary. (We know these weights as parameters from our discussion in the previous level.)

So in 2017, a paper titled Attention Is All You Need was published. It proposed a new simple neural network architecture – the transformer. A transformer is based solely on the attention mechanisms that the best performing models incorporated, thereby avoiding all those complex recurrences and convolutions. This was groundbreaking because while a recurrent network analyzes a sentence word by word, the transformer processes all the words at the same time.
It is the transformer architecture that has been instrumental in cutting down training time for a language model with 175 billion parameters from 355 years to just a few weeks. It has thus enabled the development of large-scale language models like ChatGPT by providing an efficient and effective way to process sequential data.
Level 5: Expert

This is probably where I should have stopped. Partly because the cutting-edge of AI is still blurry to most researchers and also because from this point onwards I don’t even know what I am talking about but I will try my best.
To sum up all that was explained in the previous 4 levels: ChatGPT is a chatbot built on top of an LLM – a neural network – whose basis is the transformer architecture. It was trained on a large database with the help of techniques like RLHF, sampling and temperature scaling to produce output that is aligned with human interests.
In AI, alignment refers to the idea of aligning the goals or objectives of an artificial agent with those of humans. This is important because as AI becomes more capable and autonomous, it is crucial that its objectives are aligned with human values and goals in order to avoid unintended and potentially harmful consequences.
There are many challenges for experts when it comes to alignment. It is hard to specify human values in a precise and comprehensive way, and there is a risk that an AI system's objectives may diverge from human values as it becomes more capable (more on that later). Language is inherently ambiguous and subject to interpretation, which makes it difficult to ensure that an AI system's understanding of language is aligned with human understanding.
And here comes the interesting bit – we still don’t fully understand why ChatGPT or other LLM-based tools work! There’s nothing particularly “theoretically derived” about neural nets; it’s just something that was constructed as a piece of engineering and found to work. Excitingly, that’s not much different from how we might describe our brains as having been produced through the process of biological evolution.
What’s more, recent investigations have revealed that big models can complete tasks that smaller models can’t, many of which seem to have little to do with analysing text. These are called emergent abilities, and large LLMs can produce hundreds of these! These range from multiplication to generating executable computer code to understanding offensive words in paragraphs written in Hinglish. Users started describing more and more emergent behaviours as LLMs got larger (with models like GPT-3 having 175 billion parameters), such as convincing ChatGPT that it was a Linux terminal and getting it to run some basic mathematical code to get the first of the 10 prime numbers. Notably, it completed this operation quicker than when the same code was executed on a real Linux computer!
Several emergent behaviours demonstrate “zero-shot” or “few-shot” learning. This is an LLM’s ability to solve problems it has never, or rarely, seen before. This had been a long-standing goal in AI research.
In the movie WALL-E, the protagonist develops capabilities that allow it to do things much beyond its original task of collecting garbage that it is programmed to execute such as developing emotions and falling in love. While this is of course an exaggerated example, it follows the general idea of emergent AI being able to complete tasks well beyond its expected ability.

Many researchers are now striving for a better understanding of what emergence looks like and how it arises. It presents both exciting potential and unpredictable risk.
When we understand a concept from top to bottom, we experience a certain feeling of satisfaction. I hope this edition of the Communiqué helped you get that satisfaction, while inciting curiosity about those questions that remain scientifically unanswered.
If yes, congratulations – you may now call yourself a ChatGPT expert!
The answer to where this technology is going to take us is still up for grabs. What do you think a future full of LLMs and neural nets looks like? Let us know your thoughts in the comments section below!
Very well written! Great conceptual clarity in expressing concepts like attention.